Let’s build a custom model from scratch for multiclass classification.

Outline
- Importance of building a custom model
- Basic Building Blocks of a DL
- Train and Test Data Prep
- Data loader and Image Augmentation
- Model Architecture and Training Config
- Putting everything together
- Training and Inference
- Complete Code
- Conclusion
Importance of Building a Custom Model
In the world of deep learning, we often use pre-trained models that have been trained on massive datasets. However, there are times when building a custom model from scratch is necessary. Whether you’re new to ML or an experienced pro, you’ll likely need to build your own models at some point.
Here are some key reasons why building custom ML models is important:
- Foundational Understanding: Learn Model Architecture If you’re new to ML, building models from the ground up helps you truly understand how neural network architectures work under the hood. This foundational knowledge is invaluable.
- Tailored Solutions: Fit for Your Use Case Pre-trained models may not always work well for your specific problem. Things like model size, inference speed, and required accuracy levels can make off-the-shelf models unsuitable. Building a custom model allows you to tailor it exactly to your needs.
- Unique Data Distributions: If your data distribution is very different from pre-trained model training datasets, pre-trained models may not work well. Custom models trained on your specific data can perform better.
Basic Building Blocks of any DL Model
Whether you’re fine-tuning or creating a custom model, you’ll need these main components:
i. Data Loader & Augmenter
- Converts images into numerical data the model can process.
- Various methods available for defining the data loader.
- Augmenter transforms images during training, helping the model handle real-world data variations
ii. Model Architecture:
- Can be a custom design (which we’ll cover in the next section) or a pre-trained model.
iii. Model Hyperparameters:
- Include Learning Rate, L1 & L2 Regularizers, Momentum, etc.
- Guide how model weights update
- Example: A very small learning rate prevents significant weight updates after each batch, reducing overfitting
iv. Loss Function:
- Crucial for model performance
- Determines how much to penalize model mistakes
- Choosing the right loss function is as important as selecting the model itself
v. Optimizer:
- Considers loss function output and hyperparameters to update model weights
- Various types available; selecting the right one is vital to avoid learning stagnation
vi. Training Script (Training loop)
- Select the batch of sample and passes (forward pass) through the model
- Calculates the batch loss with the loss function
- Optimizer backpropagates through the model and updates the model weights
Training and Test Data Prep
For our custom image classifier model, we’ll be using a satellite image classification dataset available on Kaggle (https://www.kaggle.com/datasets/mahmoudreda55/satellite-image-classification).

This dataset comprises 5,631 samples across four categories: cloudy, desert, green_area, and water.
After downloading the data, we’ll create a CSV file containing the image paths and their corresponding labels. Then, we’ll split this data into training and test sets. Here’s the code snippet to accomplish this:
# create a csv file with image_path and respective label
image_path_list = []
label_list = []
for class_cat in os.listdir("data"):
for image_object in os.listdir(f"data/{class_cat}"):
image_path_list.append(f"data/{class_cat}/{image_object}")
label_list.append(f"{class_cat}")
df = pd.DataFrame()
df["image_path"] = image_path_list
df["label"] = label_list
# now split this main data to train and test
# Define the split ratio
test_ratio = 0.20 # 20% of data will go to test
# split the data
train_df, test_df = train_test_split(df, test_size=test_ratio,
stratify=df['label'],
random_state=42)
print(f"Original dataset shape: {df.shape}")
print(f"Train dataset shape: {train_df.shape}")
print(f"Test dataset shape: {test_df.shape}")Above code performs the following steps:
- Iterates through the data directory to collect image paths and labels.
- Creates a pandas DataFrame with the collected information.
- Splits the data into training and test sets using
train_test_splitfrom scikit-learn. - Uses stratified sampling to ensure balanced representation of each class in both sets.
Here’s the data distribution after splitting :

Now that we have our train and test data prepared, we can proceed to define the data loader, which will be crucial for efficiently feeding the data into our PyTorch model during training and evaluation.
Dataset, Data Loader and Augmenter

After preparing our train and test image data in CSV files, we need to set up the following components:
- PyTorch image transforms: These apply a set of transformations to the input images, including augmentations for training.
- A custom PyTorch Dataset class: This loads images from local paths and applies the defined transformations.
- Train and test DataLoaders: These are responsible for loading batches of images during training and inference.
Let’s look at each of these components in detail.
PyTorch Image Transforms for Train and Test
We can define a group of image transformations using transforms.Compose([]), which accepts a list of augmentation options.
Here’s the code :
IMAGE_SIZE = 124
# this will be used during training, this will hold all the augmentation/transformation configs
training_transform = transforms.Compose([transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
# this will be used during testing / infernece, wo don't want any kind of additional transformation applied at the time of running model prediction in test / production inviroment
test_transform = transforms.Compose([transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])Note that we don’t apply any augmentations in
test_transform. This ensures that during testing or inference, the model receives the images in their original form.
Custom PyTorch Dataset Class
The PyTorch Dataset helps load images from local storage to memory, applies the defined transformations, and returns normalized torch tensors to the DataLoader.
We can use default PyTorch Dataset to load the images from disk during training, but that comes with limitation, you can refer this article I have written for more info on it.
Let’s look at the code to define a custom PyTorch Dataset :
# Define custom Dataset -> this will help you load images from your csv file
class CustomTrainingData(Dataset):
def __init__(self, csv_df, class_list, transform=None):
self.df = csv_df
self.transform = transform
self.class_list = class_list
def __len__(self):
return self.df.shape[0]
def __getitem__(self, index):
image = Image.open(self.df.iloc[index].image_path).convert('RGB')
label = self.class_list.index(self.df.iloc[index].label)
if self.transform:
image = self.transform(image)
return image, labelInitialize the custom PyTorch dataset for train and test:
train_data_object = CustomTrainingData(train_df, CLASS_LIST, training_transform)
test_data_object = CustomTrainingData(test_df, CLASS_LIST, test_transform)PyTorch DataLoader
The DataLoader is responsible for loading images in batches during training or testing. Here’s how it works:
- It selects a batch of indices, each pointing to an (image_path, label) pair.
- For each index, it calls
__getitem__(index)from our custom Dataset class. - The
__getitem__(index)method loads the image, applies transformations, and returns the tensor.
Here’s the code to create DataLoaders for our train and test datasets:
BATCH_SIZE = 32
# now define dataloader, this will load the images batches from CustomTrainingData object
train_loader = DataLoader(train_data_object, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)
test_loader = DataLoader(test_data_object, batch_size=BATCH_SIZE, shuffle=False, num_workers=4)Note: We’ve added
num_workers=4to potentially speed up data loading by using multiple processes.
With the data preparation complete, we can now move on to creating our custom model.
Define Model Architecture and Training Config
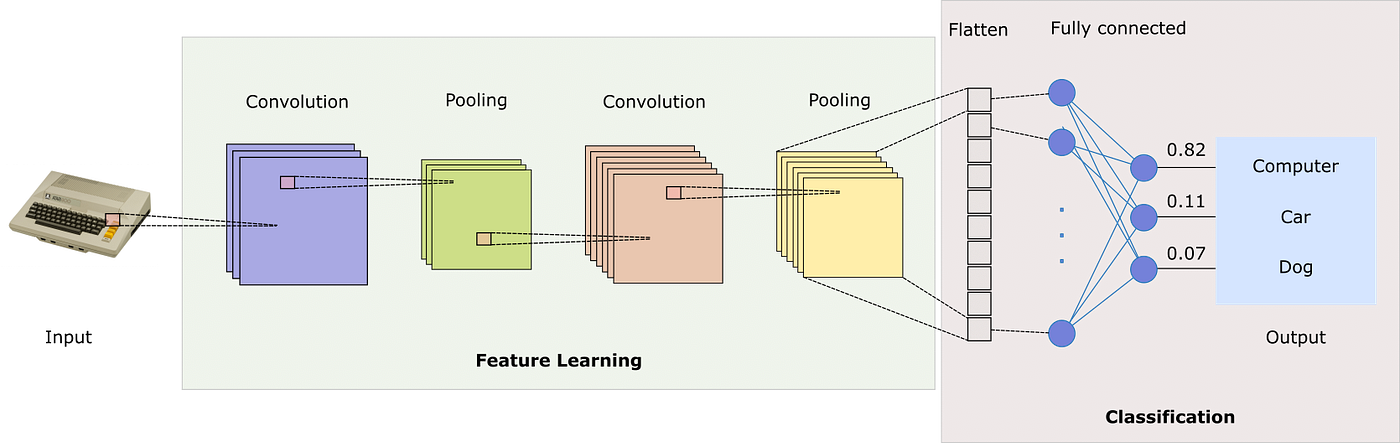
High Level Architecture of our model

Our image classification model consists of two main parts:
- Feature learning and extraction: Convolutional and Pooling layers that learn and extract features from the input images.
- Classification: Fully connected (dense) layers that use the extracted features to classify the image.
A flatten layer connects these two parts, converting the 3D output of the convolutional layers into a 1D vector for the dense layers.
Inheriting from nn.Module for custom model
We create our custom model by inheriting from nn.Module
class SatelliteImageClassifier(nn.Module)Inheriting nn.Module provides a standard interface for all neural network modules in PyTorch. It ensures our custom model integrates seamlessly with PyTorch ecosystem.
There are various reasons why inheriting nn.Module to custom model is important :
i. Automatic Parameter Management
- When you define layers as attributes of your class,
nn.Moduleautomatically registers them as parameters of your model. - This allows PyTorch to automatically track all learnable parameters for operations like optimization and serialization.
ii. GPU/CPU Compatibility
nn.Moduleprovides methods like.to(device)that move all parameters to the specified device (CPU or GPU) efficiently.
iii. State Management
- It provides methods to manage the model’s state, like
.train()and.eval(), which are crucial for processes like batch normalization and dropout.
iv. Serialization
nn.Moduleimplements methods for saving and loading model states, making it easy to save and load your trained models.
v. Forward Method
- By inheriting from
nn.Module, you're required to implement aforwardmethod, which defines the computation performed at every call.
Define Initializer method (init)
In the class initializer method, we define all the class variables and model layers. This is where you set up the structure of your neural network.
We’ll define the convolution layers, dropout, batch normalization, max/min/avg pooling, dense layers — basically what you need to build the model architecture. These layers automatically get registered as part of the model’s parameters.
Let’s look at code :
class SatelliteImageClassifier(nn.Module):
def __init__(self, num_classes, input_size=(128, 128), channels=3):
super(SatelliteImageClassifier, self).__init__()
self.input_size = input_size
self.channels = channels
# Convolutional layers
self.conv1 = nn.Conv2d(channels, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
# Batch normalization layers
self.bn1 = nn.BatchNorm2d(32)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(128)
self.bn4 = nn.BatchNorm2d(256)
# Max pooling layer
self.pool = nn.MaxPool2d(2, 2)
# Dropout layer
self.dropout = nn.Dropout(0.5)
# Calculate the size of the flattened features
self._to_linear = None
self._calculate_to_linear(input_size)
# Fully connected layers
self.fc1 = nn.Linear(self._to_linear, 512)
self.fc2 = nn.Linear(512, num_classes)In the above code:
- Convolution and MaxPool Layers are for feature extraction, helping to extract important features like shape, texture, color, etc., from the image.
- Batch Normalization (bn) and Dropout layers are there for regularizing the model during training so that the model does not overfit.
- Fully connected (FC) layers are dense layers which take the flattened output of extracted features and help in classifying the image to the right class.
We’ll see all the layers in action in the Forward() method, just bear with me :)
_calculate_to_linear() method
- This function calculates the size of the flattened features given the input image size.
_to_lineardefined in the init class maintains the size of the flattened layer output.
Here’s code:
def _calculate_to_linear(self, input_size):
# This function calculates the size of the flattened features
x = torch.randn(1, self.channels, *input_size)
self.conv_forward(x)The forward method (the real deal)
The forward() method is core to building PyTorch models and it does a lot of work under the hood.
The core functionality of
forward()method is to defines the computation performed on the input data like how how data flows through the layers of your neural network.
When we call the model on an input (e.g., output = model(input)), PyTorch automatically invokes the forward() method.
forward() method helps define the network architecture:
- It’s where we implement the actual sequence of operations that transform the input to the output.
- We define how the layers interact and in what order they are applied.
- We can call other modules or methods within
forward(), allowing for modular design of complex networks.
Let’s look at the code :
def conv_forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x))))
x = self.pool(F.relu(self.bn2(self.conv2(x))))
x = self.pool(F.relu(self.bn3(self.conv3(x))))
x = self.pool(F.relu(self.bn4(self.conv4(x))))
if self._to_linear is None:
self._to_linear = x[0].shape[0] * x[0].shape[1] * x[0].shape[2]
return x
def forward(self, x):
x = self.conv_forward(x)
# Flatten the output for the fully connected layer
x = x.view(-1, self._to_linear)
# Fully connected layers with ReLU and dropout
x = self.dropout(F.relu(self.fc1(x)))
x = self.fc2(x)
return xIn above code `conv_forward` :
In each line, we have defined the same computation, just that the conv or bn layers change. Let’s take one conv + pooling layer for example:
x = self.pool(F.relu(self.bn1(self.conv1(x))))- First, we pass the input through
self.conv1()convolution layer - Then the output is passed on to
self.bn1()batch normalization - The ReLU activation function is applied to the bn1 output
- Output from ReLU is passed on to
self.pool()pooling layer.
The simplified form of this one-liner can be written as:
# Apply convolution
x = self.conv1(x)
# Apply batch normalization
x = self.bn1(x)
# Apply ReLU activation function
x = F.relu(x)
# Apply max pooling
x = self.pool(x)In the above code, forward:
conv_forward(self, x)is called inside forward, showing how we can have modular design of neural networks.- First, the input is passed through
conv_forwardwhich applies convolution and pooling on the input. - Then
x.view(-1, self._to_linear)flattens the output from convolution/feature extraction - And then the flattened output is passed on to the fully connected layers.
We can use Python control flow (if statements, loops) within
forward(), allowing for more complex and flexible architectures. We can also implement custom operations or logic that aren't pre-defined PyTorch layers.
Complete model architecture code :
class SatelliteImageClassifier(nn.Module):
def __init__(self, num_classes, input_size=(128, 128), channels=3):
super(SatelliteImageClassifier, self).__init__()
self.input_size = input_size
self.channels = channels
# Convolutional layers
self.conv1 = nn.Conv2d(channels, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
# Batch normalization layers
self.bn1 = nn.BatchNorm2d(32)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(128)
self.bn4 = nn.BatchNorm2d(256)
# Max pooling layer
self.pool = nn.MaxPool2d(2, 2)
# Dropout layer
self.dropout = nn.Dropout(0.5)
# Calculate the size of the flattened features
self._to_linear = None
self._calculate_to_linear(input_size)
# Fully connected layers
self.fc1 = nn.Linear(self._to_linear, 512)
self.fc2 = nn.Linear(512, num_classes)
def _calculate_to_linear(self, input_size):
# This function calculates the size of the flattened features
x = torch.randn(1, self.channels, *input_size)
self.conv_forward(x)
def conv_forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x))))
x = self.pool(F.relu(self.bn2(self.conv2(x))))
x = self.pool(F.relu(self.bn3(self.conv3(x))))
x = self.pool(F.relu(self.bn4(self.conv4(x))))
if self._to_linear is None:
self._to_linear = x[0].shape[0] * x[0].shape[1] * x[0].shape[2]
return x
def forward(self, x):
x = self.conv_forward(x)
# Flatten the output for the fully connected layer
x = x.view(-1, self._to_linear)
# Fully connected layers with ReLU and dropout
x = self.dropout(F.relu(self.fc1(x)))
x = self.fc2(x)
return xModel Hyperparameters and Config
Let’s define some model hyperparameters and config. We’ll use these in the training script and some while initializing the model.
# list of classes in your dataset
CLASS_LIST = ['water', 'cloudy', 'desert', 'green_area']
# Hyperparameters
BATCH_SIZE = 124
BATCH_SIZE = 32
EPOCHS = 25
LEARNING_RATE = 0.001
NUM_CLASSES = len(CLASS_LIST)
INPUT_SIZE = (IMAGE_SIZE, IMAGE_SIZE)
CHANNELS = 3
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')Initialize our Custom Model
We can create the model by initializing the SatelliteImageClassifier with NUM_CLASSES, INPUT_SIZE, and CHANNELS.
We'll assign the model to GPU with .to(device). This will pick the available GPU; otherwise, it will load the model on CPU.
# Initialize the model
model = SatelliteImageClassifier(NUM_CLASSES, INPUT_SIZE, CHANNELS).to(device)Let’s set the optimizer with the learning rate. We’re using Adam in this instance, and CrossEntropyLoss as our loss function.
# Loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)To see the total number of parameters:
# If you want to see the number of parameters
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params}")
Let’s print the model :

Let’s Recap

So far, we’ve covered the following key steps in building our custom PyTorch image classifier:
i. Data Preparation:
- We defined image transformations:
training_transformandtest_transform - We created a Custom Dataset class for both training and testing data
- We initialized
train_data_objectandtest_data_objectusing our custom dataset class
ii. Data Loading:
- We created PyTorch DataLoaders (
train_loaderandtest_loader) to efficiently load batches of images during training and testing
iii. Model Architecture:
- We defined a custom class
SatelliteImageClassifierthat inherits fromnn.Module - We implemented the
__init__method to set up our model's layers - We created the
forwardmethod to define how data flows through our network
iv. Model Initialization:
- We initialized our custom model with the appropriate parameters
v. Training Setup:
- We defined the optimizer (Adam) to update our model’s parameters
- We chose an appropriate loss function (CrossEntropyLoss) for our multi-class classification task
Now that we have all these components in place, we’re ready to bring them together in a training loop and start training our model.
Training Loop
The training loop is the heart of the model training process. It involves running the same sequence of steps for a certain number of epochs (iterations). During each epoch:
- We select batches of images and pass them through the model
- We calculate the loss for each batch using our defined loss function
- We use the optimizer to update the model weights based on the calculated loss.
Here’s code for the training loop :
Please note, this training script is highly simplified. Many important elements such as logging, plotting, saving best and last weights, using callbacks, and integrating TensorBoard have been omitted to maintain simplicity..
# Training loop
for epoch in range(EPOCHS):
model.train()
running_loss = 0.0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch [{epoch+1}/{EPOCHS}], Loss: {running_loss/len(train_loader):.4f}')
# Validation
model.eval()
all_predictions = []
all_labels = []
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
all_predictions.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
# Calculate metrics
accuracy = 100 * sum(np.array(all_predictions) == np.array(all_labels)) / len(all_labels)
precision = precision_score(all_labels, all_predictions, average='weighted')
recall = recall_score(all_labels, all_predictions, average='weighted')
f1 = f1_score(all_labels, all_predictions, average='weighted')
print(f'Epoch [{epoch+1}/{EPOCHS}]')
print(f'Accuracy on test set: {accuracy:.2f}%')
print(f'Precision: {precision:.4f}')
print(f'Recall: {recall:.4f}')
print(f'F1 Score: {f1:.4f}')
print('-----------------------------')
print('Training finished!')
# Save the model
torch.save(model.state_dict(), 'satellite_classifier.pth')
Let’s break down some key components of this training loop:
model.train()andmodel.eval(): These set the model for training and evaluation modes respectively. In eval mode,model.eval()disables regularization techniques like dropout and batch normalization, which are only used during training.optimizer.zero_grad(): This resets the gradients of all parameters to zero before the backward pass. It's necessary because PyTorch accumulates gradients by default.loss = criterion(outputs, labels): This calculates the loss for the given batch using our defined loss function.loss.backward(): This computes the gradient of the loss with respect to the model parameters.optimizer.step(): This updates the model parameters based on the computed gradients.with torch.no_grad():: This context manager is used during validation to disable gradient calculation, which speeds up computation and reduces memory usage.torch.save(model.state_dict(), 'satellite_classifier.pth'): This saves the model weight at the end of training.
I would highly highly recommend reading this article, in this article i have covered multiple aspect of fine tuning model in PyTorch, give it a read :)
Now that we’ve trained our model and saved it to disk, let’s move on to loading the model and running inference on new data.
Running Model Inference
After training our model and saving it to disk, we can load it for inference on new images. Let's go through the process step by step.
Loading the Saved Model
To load your saved model:
- Import necessary modules and your custom model class.
- Instantiate your
SatelliteImageClassifiermodel. - Load the saved state dictionary using
torch.load(). - Apply the loaded state dictionary to your model instance.
- Set the model to evaluation mode if you’re using it for inference.
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
INPUT_SIZE = (124, 124)
CHANNELS = 3
# create model object from SatelliteImageClassifier class
model = SatelliteImageClassifier(NUM_CLASSES, INPUT_SIZE, CHANNELS)
# Load the saved state dictionary
state_dict = torch.load('satellite_classifier.pth')
# Load the state dictionary into your model
model.load_state_dict(state_dict)
# Set the model to evaluation mode
model.to(device).eval()Define Image Transforms and Class List
We need to ensure that we process new images in the same way as our training data:
# this will be used during testing / infernece, wo don't want any kind of additional transformation applied at the time of running model prediction in test / production inviroment
test_transform = transforms.Compose([transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
CLASS_LIST = ['water', 'cloudy', 'desert', 'green_area'] # list of classes in your datasetHelper Function to Plot Images
Let’s create a function to display the images we’re classifying:
def plot_image(image):
"""
Plot an image using matplotlib.
Parameters:
image : PIL.Image or numpy.ndarray
The image to be plotted. Can be a PIL Image object or a numpy array.
"""
# Convert PIL Image to numpy array if necessary
if isinstance(image, Image.Image):
image = np.array(image)
plt.imshow(image)
plt.axis('off') # Hide axes
plt.show()Inference Function
Now, let’s write a function that takes an image path as an argument, plots the image, and prints the model’s prediction:
# Inference script
def predict(image_path):
image_pil = Image.open(image_path).convert('RGB')
image = test_transform(image_pil).unsqueeze(0).to(device)
with torch.no_grad():
output = model(image)
# Apply softmax to the output
softmax_output = F.softmax(output, dim=1)
print(f'Model raw output: {output}')
print(f'Softmax output: {softmax_output}')
# Get the predicted class and its confidence
confidence, predicted = torch.max(softmax_output, 1)
predicted_class = CLASS_LIST[predicted.item()]
confidence = confidence.item()
print(f'Predicted class: {predicted_class}')
print(f'Confidence: {confidence:.4f}')
plot_image(image_pil)Running Inference
Now we can use our predict_image function to classify new images:
Example 1:

Model raw output: tensor([[ -1.5463, -5.0433, -20.4949, 23.9693]], device='cuda:0')
Softmax output: tensor([[8.2927e-12, 2.5117e-13, 4.8916e-20, 1.0000e+00]], device='cuda:0')
Predicted class: green_area
Confidence: 1.0000Example 2:

Model raw output: tensor([[ 4.0157, -7.6036, -12.5321, 3.6128]], device='cuda:0')
Softmax output: tensor([[5.9936e-01, 5.3889e-06, 3.9004e-08, 4.0063e-01]], device='cuda:0')
Predicted class: water
Confidence: 0.5994Get access to complete code here : https://github.com/rumanxyz/pytorch-model-code/blob/main/custom-image-classifier/image_classifier_from_scratch.ipynb
Conclusion
In this article, we’ve explored the various aspects of creating a custom image classification model in PyTorch. We’ve covered a comprehensive journey from data preparation to model inference, touching on several crucial components:
- Data Preparation: We learned how to create custom datasets and use PyTorch’s DataLoader for efficient batch processing.
- Model Architecture: We delved into the structure of a PyTorch model by subclassing
nn.Module. We explored important methods like__init__()andforward(), and understood how they contribute to defining our model's architecture. - Training Process: We implemented a training loop, incorporating concepts like loss calculation, backpropagation, and optimization.
- Model Evaluation: We included validation steps in our training process to monitor our model’s performance on unseen data.
- Inference: Finally, we learned how to save our trained model, load it, and use it for making predictions on new images.
Throughout this process, we’ve gained hands-on experience with key PyTorch concepts and best practices for building custom neural networks. This foundation can be extended to more complex architectures and applied to a wide range of computer vision tasks beyond satellite image classification.
If you enjoyed this article, your applause would be greatly appreciated!


{kind=link}